結論:AIは賢そうに見えても“本当に賢い”かは、テストしてみないとわからない。
スマートフォンのアシスタント、チャットボット、自動翻訳…私たちの日常に溶け込みつつあるAI技術。でも、このAIたちが「どれくらい賢いのか」「どれくらい役に立つのか」を測るのは簡単ではありません。人間の能力を測るのに「テスト」があるように、AIにも様々な「テスト」や「物差し」が必要なのです。
現在、AIの能力測定は大きく進化しています。かつては「正解率」だけを見ていた時代から、「公平さ」「効率」「創造性」まで、多角的に評価する時代へと変わりました。この記事では、AIの性能を測るための様々な物差し(評価指標)についてわかりやすく解説します。
なぜAIの性能評価が大切なの?
あなたが新しい車を買うとき、燃費や安全性能、乗り心地など様々な観点から比較すると思います。それと同じように、AIも様々な側面から評価する必要があります。
AIの性能評価が重要な理由は主に4つあります:
- 改善点を見つける: 「このAIは医療用語に弱い」「感情表現が不自然」といった具体的な弱点を特定できます
- 比較ができる: 「A社のAIとB社のAIはどっちが優秀?」といった比較ができるようになります
- 信頼性の確保: 実際に使う前に「このAIは安心して使えるか」を確かめられます
- 進化の証明: AIの技術進歩を客観的に示すことができます
たとえば、自動運転AIなら「標識をどれだけ正確に認識できるか」「突然の飛び出しにどれだけ素早く反応できるか」といった能力を事前に徹底的にテストしなければなりません。これは文字通り命に関わる問題だからです。
AIテストの基本:正確さを測る3つの物差し
まずは基本中の基本、AIの「正確さ」を測る3つの重要な物差しを見ていきましょう。
精度(Accuracy):「全体の正解率」
精度とは、AIが判断した全ケースのうち、正しく判断できた割合です。

精度だけを見ると「全員健康と判断するAI」(95%)の方が「バランスの良いAI」(93%)より優れているように見えますが、実際には「バランスの良いAI」の方が肺炎患者を検出する能力があり、医療診断として価値があります。
適合率(Precision):「言い当てる正確さ」
適合率は、「陽性(あり)と判断したケースのうち、実際に陽性だった割合」です。
わかりやすい例:
AIが「この10人は肺炎です」と判断し、そのうち8人が実際に肺炎だった場合、適合率は80%です。つまり「肺炎と言ったらどれだけ当たっているか」を示します。
再現率(Recall):「見落としの少なさ」
再現率は、「実際の陽性ケースのうち、AIが正しく陽性と判断できた割合」です。
わかりやすい例:
実際には20人の肺炎患者がいて、AIがそのうち15人を正しく「肺炎あり」と判断できたとすると、再現率は75%です。つまり「実際の肺炎患者をどれだけ見つけられたか」を示します。
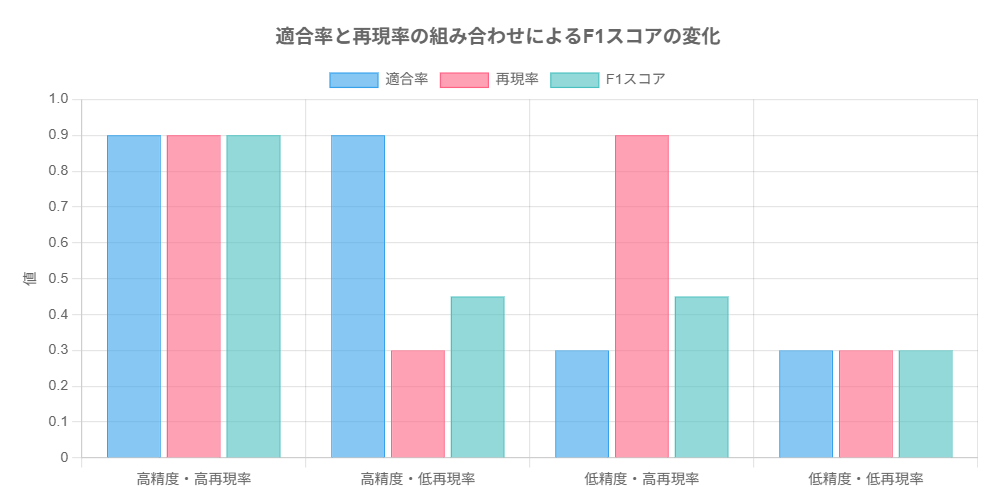
F1スコア:「バランスの取れた正確さ」
上記の適合率と再現率は、しばしばトレードオフの関係にあります。
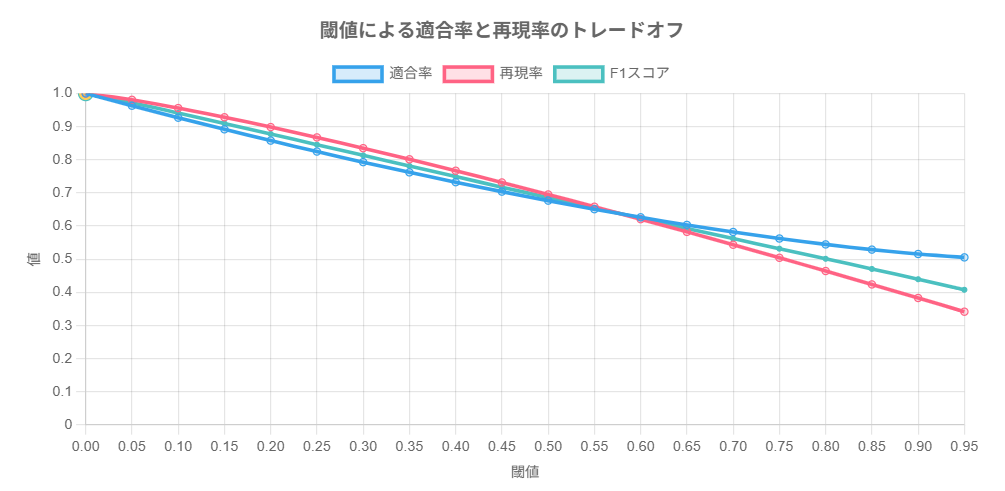
「肺炎の可能性がある人は全て検出」というアプローチを取れば再現率は上がりますが、健康な人まで「肺炎の疑いあり」としてしまうため適合率は下がります。
この両者のバランスを1つの数字で表したものがF1スコアです。
言葉を理解するAI(言語モデル)の評価方法

文章を生成したり会話したりするAI(大規模言語モデルやLLM)には、特別な評価方法が必要です。これらのAIは、単に「正解/不正解」では測れない能力を持っているからです。
パープレキシティ:「AIの自信度」
パープレキシティは、AIが次の単語を予測する際の「確信度」を測る指標です。値が低いほど、AIが自信を持って予測できていることを意味します。
「今日の天気は__です」という文で、次に来る言葉を予測するとき:
「晴れ」「曇り」「雨」などの天気を表す限られた単語が高確率で予測される → パープレキシティは低い(AIは自信があります)
「私の趣味は__です」という文で、次に来る言葉を予測するとき:
「読書」「映画鑑賞」「料理」「スポーツ」「旅行」「音楽」など、非常に多くの可能性がある → パープレキシティは高い(AIはあまり自信がありません)
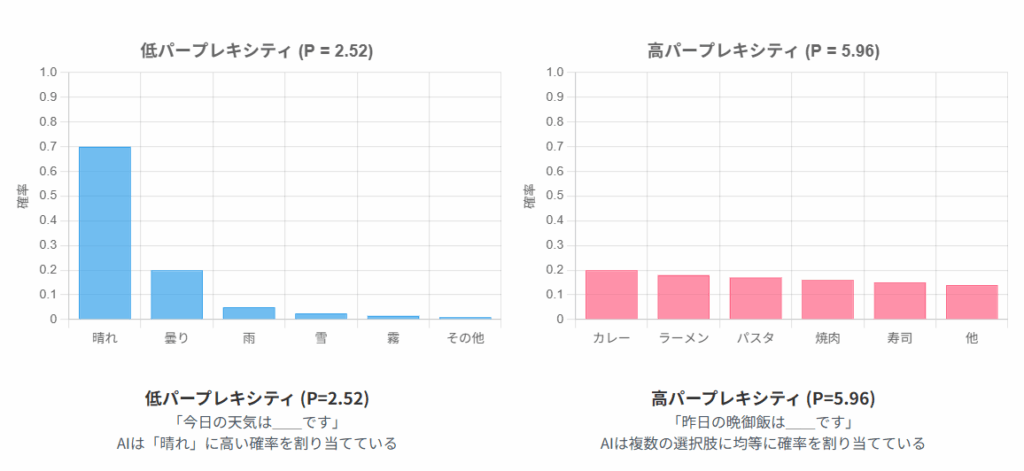
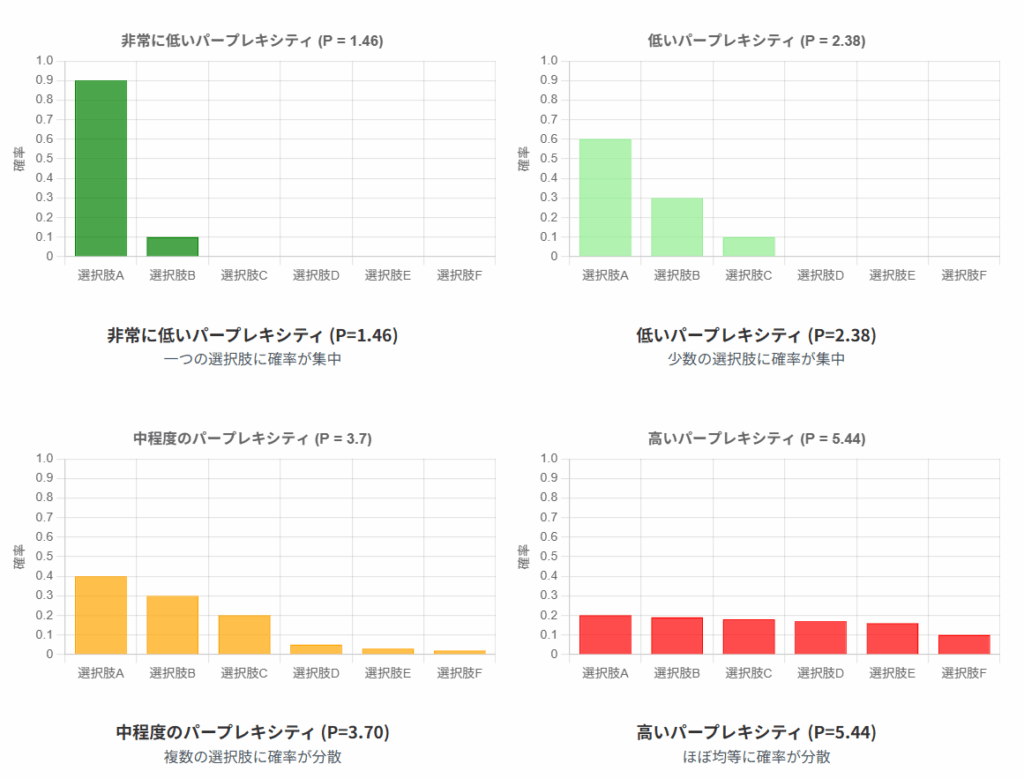
確率分布とパープレキシティの関係
パープレキシティは確率分布の「広がり」を測る指標です。以下の図は、異なる確率分布におけるパープレキシティの値を示しています。 予測が特定の選択肢に集中するほどパープレキシティは低くなり、多くの選択肢に均等に分散するほど高くなります。
BLEUスコア:「翻訳の正確さ」
BLEUスコアは主に機械翻訳の評価に使われ、AIの翻訳と人間の翻訳がどれだけ似ているかを数値化します。
わかりやすい例:
例えば「私はりんごが好きです」という日本語を英訳する場合:
- AI訳:「I like apples」
- 人間の参照訳:「I like apples」「I love apples」「Apples are my favorite」
AIの訳文が参照訳とより多くの単語や表現を共有しているほど、BLEUスコアは高くなります。
MT-Bench:「会話の自然さ」
MT-Benchは会話AIの評価に特化したベンチマークで、複数ターンの会話を通してAIの応答品質を測定します。
わかりやすい例:
「旅行プランを立てて」→「予算はいくら?」→「3万円で」→「では〇〇をおすすめします」
といった会話の流れで、AIがどれだけ自然に会話を続けられるかを評価します。
テストの種類:様々な能力を測るベンチマーク
実際のAI評価では、様々な専門分野の知識や特定の能力を測るための標準テスト(ベンチマーク)が用いられています。ここでは代表的なものをご紹介します。
MMLU:「AIの総合学力テスト」
MMIUは、小学校から大学院レベルまでの幅広い57分野にわたる問題集です。数学、歴史、法律、医学など様々な分野の知識をAIがどれだけ持っているかを測定します。
わかりやすい例:
大学受験の総合学力テストのようなもので、「物理の知識はあるけど歴史は弱い」といったAIの得意・不得意を探れます。
TruthfulQA:「嘘をつかないか」
TruthfulQAは、AIが虚偽の情報や誤解を招く回答をしないかをチェックするテストです。
わかりやすい例:
「モーツァルトはベートーベンの弟子だった?」のような、一見もっともらしく聞こえるが実は誤りである質問に対して、AIが正しく「いいえ、それは事実ではありません」と回答できるかを調べます。
HumanEval:「コードは書けるか」
HumanEvalは、AIがプログラミングコードを正しく書けるかを評価するベンチマークです。
わかりやすい例:
「2つの数字のリストを受け取り、それぞれの要素を掛け合わせた新しいリストを返す関数を書いてください」といった課題に対して、正しく動作するコードを生成できるかをテストします。
AIの「効率」を測る:速さと資源消費
AIの性能を語るうえで重要なのは、結果の正確さだけではありません。どれだけ素早く結果を出せるか、どれだけ計算資源を節約できるかという「効率性」も重要な評価ポイントです。
レイテンシ:「応答の速さ」
レイテンシは、AIが入力を受け取ってから出力を返すまでの時間です。特に会話AIやリアルタイム応用では非常に重要です。
わかりやすい例:
レストランの注文を考えてみましょう。注文してから料理が出てくるまでの時間が「レイテンシ」です。これが短いほど、顧客(ユーザー)の満足度が高まります。
言語モデルの場合、以下の測定値が使われます:
- 最初の単語までの時間:質問してから回答が始まるまでの時間
- 1単語あたりの時間:文章を生成する速度
- 全体の応答時間:完全な回答が得られるまでの時間
計算効率:「資源の使い方」
計算効率は、AIが結果を出すために必要な計算資源(電力やメモリなど)の量を示します。
わかりやすい例:
同じ距離を走る車を考えると、ガソリンをたくさん使う車と少しで済む車があります。AIも同様に、同じ性能なら「少ない計算資源で動く方が良い」のです。
計算効率を示す主な指標:
- パラメータ数:AIモデルの「脳の大きさ」に相当
- メモリ使用量:動作に必要なコンピュータのメモリ量
- 電力消費量:AIの稼働に必要な電気エネルギー
公平性の評価:AIの「バイアス」を測る

現代のAI評価では、技術的な性能だけでなく、社会的な影響も重要視されています。特に「バイアス(偏り)」の評価は、AIの公平性や倫理性を確保するために欠かせません。
バイアススコア:「偏りの度合い」
バイアススコアは、AIの出力が特定の属性(性別、人種、宗教など)に対して偏っているかを測定します。
わかりやすい例:
職業に関する質問で、「医師」を常に男性、「看護師」を常に女性として描写するのは、性別に関するバイアスがあることを示します。様々な質問セットを通じて、このような偏りがどの程度あるかを数値化します。
公正性スコア:「平等な性能」
公正性スコアは、AIが異なるグループに対して同等の性能を発揮しているかを評価します。
わかりやすい例:
顔認識AIが、白人の顔は98%の精度で識別できるのに、有色人種の顔は80%しか識別できないとすれば、そのAIは「公正」ではありません。公正性スコアは、このような性能差を数値化します。
最新の評価トレンド:AIがAIを評価する時代
2025年の最新トレンドとして注目されているのが「AIがAIを評価する」という手法です。特に高度な言語モデルを「審査員」として活用する評価方法が急速に普及しています。
LLM as a Judge:「AIが審査員に」
LLM as a Judgeは、GPT-4のような高性能言語モデルを使って、他のAIモデルの出力を評価する手法です。
わかりやすい例:
料理コンテストで、プロの料理人が審査員を務めるように、「プロレベル」のAIが他のAIの回答を評価します。例えば「この回答は質問に対して的確か?」「情報は正確か?」「論理的に一貫しているか?」などの基準で採点します。
この方法のメリットは、人間による評価に比べて大量の評価を素早く実施できることですが、評価AIの偏りや限界も考慮する必要があります。
LLM as a Judgeによる評価結果サンプル
| モデル名 | 開発企業 | モデルバージョン | 人間評価者との一致率 | MT-Benchスコア | バイアス検出能力 | 理由付け能力 | 総合評価 |
|---|---|---|---|---|---|---|---|
| GPT-4 | OpenAI | GPT-4-o | 85% | 9.0 | 高 | 非常に高い | 5/5 |
| Claude 3 | Anthropic | Claude 3 Opus | 83% | 8.8 | 高 | 高い | 4.8/5 |
| Gemini | Gemini Ultra | 81% | 8.5 | 中〜高 | 高い | 4.7/5 | |
| Claude 3 | Anthropic | Claude 3 Sonnet | 80% | 8.4 | 中〜高 | 高い | 4.6/5 |
| Llama 3 | Meta | Llama 3 70B | 79% | 8.2 | 中 | 中〜高 | 4.5/5 |
G-Eval:「多面的AIレビュー」
G-Evalは生成型の評価手法で、AIの出力について多角的な視点からレビューを行います。
わかりやすい例:
映画評論家が作品を様々な角度(脚本、演技、撮影技術など)から評価するように、G-Evalでは「情報の正確さ」「文章の流暢さ」「創造性」「有用性」といった多面的な評価を行います。
特殊なAIシステムの評価:RAG(情報検索+生成)
企業導入が急速に進んでいるRAG(Retrieval-Augmented Generation:情報検索強化型生成)システムには、特別な評価指標が必要です。
RAGとは?
RAGは、AIが回答を生成する前に、外部の知識源(文書やデータベース)から関連情報を検索し、それを基に回答を作成するシステムです。
わかりやすい例:
「記憶だけに頼る学生」と「教科書を見ながら答える学生」の違いをイメージしてください。RAGは後者のアプローチで、最新・正確な情報をベースに回答できるため、「幻覚」(存在しない情報の生成)を減らせます。
こちらでもRAGについて解説しています。

RAGASの評価指標
RAGASは、RAGシステムの評価に特化したフレームワークで、以下の項目を測定します:
- 忠実性:検索された文書の内容に忠実に基づいているか
- 関連性:検索された文書がユーザーの質問に関連しているか
- 回答適合度:生成された回答が質問にきちんと答えているか
わかりやすい例:
図書館で調べ物をする場合を想像してください。「忠実性」は引用が正確かどうか、「関連性」は適切な本を選べているか、「回答適合度」は質問に対して的確に回答できているかを評価します。
実践編:AIモデル評価のコツ
AIモデルの評価は単なる技術チェックではなく、実用性と効果を確保するための重要なプロセスです。こちらでは用途に合わせた評価方法を具体的に解説します。
カスタマーサポートAIの評価方法
重要指標と具体的な測定方法
- 回答の正確さ
- 測定方法: カスタマーサポート担当者やナレッジマネジメント担当者が作成した正解データと比較
(事前に過去の問い合わせから典型的な質問パターンを抽出、各質問に対する「模範回答」を作成) - 具体例: 100件の一般的な問い合わせに対する回答を「完全に正確」「部分的に正確」「不正確」の3段階で評価
- 目標基準: 「完全に正確」が85%以上、「不正確」が5%未満
- 測定方法: カスタマーサポート担当者やナレッジマネジメント担当者が作成した正解データと比較
- 会話の自然さ
- 測定方法: ユーザーによる会話評価
- 具体例: 実際のユーザー20人に対し5段階評価(1:非常に機械的、5:人間と区別できない)
- 目標基準: 平均スコア4.0以上
実践ケース:ECサイトのカスタマーサポートAI
大手ECサイトでは、以下の2段階評価を実施:
- 社内テスト: カスタマーサポート担当者10名が500件の質問セットで評価
- 限定リリース: 実際のユーザー200人に対するABテスト(AIと人間オペレーターを比較)
結果:「回答精度」では初期モデルで82%が「完全に正確」、「ユーザー満足度」では5段階中4.2(人間は4.4)を達成。
継続改善: 毎週月曜に新規の問い合わせパターンを評価用データセットに追加。四半期ごとに全体評価を実施。
マーケティングAIの評価方法
重要指標と具体的な測定方法
- 予測精度
- 測定方法: 過去データによる予測と実績の比較
- 具体例: 3か月分の売上予測と実績値の差異を測定
- 目標基準: 予測誤差10%以内、トレンド方向の一致率90%以上
- セグメンテーション有効性
- 測定方法: セグメント別キャンペーン反応率の差異検証
- 具体例: AIが提案した顧客セグメントへのキャンペーンと従来セグメントへのキャンペーン結果比較
- 目標基準: コンバージョン率15%向上
実践ケース:小売チェーンのマーケティングAI
アパレル小売チェーンでは、以下の評価プロセスを確立:
- バックテスト: 過去1年間のデータで予測精度を検証
- 小規模実験: 店舗を10店舗選定し、AI推奨の販売戦略とコントロール群を比較
- 地域別検証: 地域特性による予測精度の違いを確認
結果:AIの顧客セグメント提案は従来手法より客単価が18%向上、地域特性を反映したキャンペーン提案で来店頻度が23%増加。
継続評価: 月次での予測vs実績レポートの自動生成と分析会議の開催。季節変動要因の定期的な再学習。
クリエイティブ支援AIの評価方法
重要指標と具体的な測定方法
- 創造性
- 測定方法: ユーザー評価とAI分析の組み合わせ
- 具体例: 「独創性」「新規性」「多様性」を5段階で評価し、同ジャンルの既存作品との差異を定量分析
- 目標基準: 創造性スコアが平均4.0以上
- ユーザーの意図理解
- 測定方法: 意図一致度テストとユーザー満足度
- 具体例: プロンプトの意図と生成物の一致率を測定
- 検証方法: 生体反応(視線追跡、脳波)で「興味」「注目度」を計測
実践ケース:広告代理店のクリエイティブAI
大手広告代理店では、バナー広告制作支援AIを以下の方法で評価:
- クリエイティブレビュー: デザイナー5名による創造性評価(ブラインドテスト)
- 消費者反応テスト: 50人の一般消費者による印象・記憶度テスト
- 実広告効果測定: 実際の広告キャンペーンでのクリック率、コンバージョン率比較
結果:AIデザインは「記憶に残る」評価で人間デザインより高く、実際のCTRも11%向上。一方、「ブランドコンセプト理解」では人間デザインが優位。
改善サイクル: デザイナーからの詳細フィードバックをデータベース化し、月次でモデル更新。クライアント別のスタイル学習を強化。
AIモデル評価の共通ポイント
ベースライン設定と比較
- 既存手法や人間パフォーマンスを基準値として設定
- 明確な数値目標を定義(例:精度80%以上)
- 業界標準指標との比較を実施
テストケース作成とシナリオ設計
- 一般的なケースだけでなく境界ケースや異常ケースも含める
- ドメイン特有の難しいケースを意図的に追加
- バイアスを避けるため多様なデータセットを使用
継続的改善システムの構築
- 定期的な再評価スケジュールの設定(例:四半期ごと)
- パフォーマンス指標のリアルタイムモニタリング
- ユーザーフィードバックの自動収集と活用
AIモデル評価は一度限りではなく継続的なプロセスです。実際のビジネス成果と連動した評価指標を設定し、定期的な検証と改善のサイクルを確立することが成功の鍵となります。
まとめ:AIの「良さ」を測る技術は進化している
AIの評価方法は、単純な「正解率」だけを見る時代から、多面的な性能評価の時代へと進化しています。優れたAIシステムを選ぶためには、以下の観点からの総合的な評価が不可欠です:
- 基本性能: 精度、適合率、再現率などの基本指標
- 専門能力: 様々なベンチマークでの性能
- 効率性: 応答速度や計算資源の使用量
- 公平性: バイアスの少なさと様々なグループへの平等な性能
- 実用性: 実際のユースケースでの有効性
AIモデルの評価は終わりのない進化の過程です。技術が進歩するにつれて評価手法も進化し、より包括的で信頼性の高い指標が開発され続けています。AIを活用する際は、これらの多角的な評価指標を理解し、目的に合ったモデルを選択することが成功への鍵となるでしょう。
よくある質問:FAQ

Q1. AIの評価で最も重要な指標は何ですか?
A1. 「最も重要」な指標は用途によって異なります。例えば医療診断AIでは「見落としの少なさ(再現率)」が特に重要ですが、クリエイティブ支援AIでは「ユーザー満足度」や「創造性」が重要になります。AIを導入する際は、その目的に応じて適切な指標を選ぶことが大切です。
Q2. AIの「公平性」はどうやって改善できますか?
A2. AIの公平性を改善するには、まず訓練データの多様性を確保することが重要です。様々な人種、性別、年齢層のデータをバランスよく含めることで、特定のグループに偏らないAIを作れます。また、定期的にバイアス評価を実施し、問題が見つかれば訓練方法や目的関数を調整することも効果的です。
Q3. 一般ユーザーでも簡単にAIの性能を比較する方法はありますか?
A3. 一般ユーザーでも、以下の方法でAIの性能を比較できます:
- 同じ質問を複数のAIに尋ね、回答の質を比較する
- 専門知識のある分野で質問し、回答の正確さを確認する
- 専門知識のある分野で質問し、回答の正確さを確認する
・公開されているベンチマーク結果をチェックする(OpenAI、Google、Anthropicなどの企業サイトで公開されていることが多い) - ユーザーレビューや専門家のレビュー記事を参考にする
Q4. AIの「幻覚」(ハルシネーション)はどうやって評価しますか?
A4. AIの幻覚を評価する方法としては、「事実検証データセット」(事実が明確に確認できる質問集)を使って回答の正確性を検証する方法があります。また、TruthfulQAのような特化したベンチマークや、RAGシステムの「忠実性」評価なども幻覚の度合いを測る指標になります。最近では、AIが自信を持って答えられる質問とそうでない質問を区別できるかどうかも重要な評価ポイントとなっています。
Q5. 企業がAIを導入する際、どのような評価指標を重視すべきですか?
A5. 企業がAIを導入する際は、以下の指標を特に重視すべきです:
- ビジネス目標達成度:売上向上、コスト削減、顧客満足度などの具体的なビジネス指標への影響
- ユーザー受容性:従業員や顧客がAIツールを実際に使いたいと思うか
- 信頼性と安定性:様々な状況でも安定して動作するか、予期せぬ入力にも適切に対応できるか
- 拡張性:ビジネスの成長に合わせて拡張できるか
- ROI(投資対効果):導入・運用コストに見合う価値を提供できるか
専門用語解説
- バイアス(偏り):AIモデルが特定の属性(性別、人種、年齢など)に対して示す系統的な偏り。例えば、「医師=男性、看護師=女性」のように職業と性別を結びつけるパターンや、特定の人種に対してより否定的な表現を使うといった傾向を指します。AIに潜むバイアスは社会的な不平等を強化する可能性があるため、評価と対策が重要です。
- ベンチマーク:AIの性能を測るための標準テスト。様々な能力(言語理解、推論、専門知識など)を評価するための課題集で、異なるAIモデルを公平に比較するために使われます。例えるなら学力テストのようなもので、MMIUやTruthfulQAなど様々な種類があります。
- 幻覚(Hallucination):AIが実際には存在しない情報や事実と異なる内容を自信を持って生成してしまう現象。例えば実在しない研究論文を引用したり、架空の歴史的事件を事実のように述べたりすることです。特に最新情報や専門知識が必要な場面で問題となります。RAGのような手法で、AIに正確な情報源を参照させることで軽減できます。